판다스 라이브러리를 불러오고 사이트에 있는 csv(엑셀)파일을 불러와서 그 이름을 store_sales라고 지정했다.
상품 2개 p1,p2의 설명을 알려주는 데이터 프레임이다.
데이터 구조를 확인할수있다.상점의 번호를 식별한다. range임으로 101부터 101+n_stores-1 까지의 번호가 할당된다.국가도 마찬가지로 지정해준다.타입을 체크할수가있다. 타입체크는 코드를 짤때 중간중간에 확인할수있는 case가 생긴다.
zip은 압축하고 반복하는 함수이다.
astype는 판다스에서 데이터프레임 형태를 바꿔주는 함수이다.pd.CategoricalDtype() 은 범주형 데이터 타입을 지정하기 위해 사용된다.
3.1.2 데이터 시뮬레이션
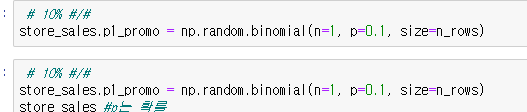
binomial. bi가 있으므로 2개, 즉 이항분포이다. p는 probability 당연히 확률이고 n은 개수이다.
코드를 해석해 보자면 p1.promo는 p=0.1 의해서 10%의 확률로 1이 된다. 90%의 확률로는 0이 되겠죠 ㅎㅎ
실제로 1871의 1/9는 187+18=205정도인데 209와 유사하다.이것도 마찬가지로 choice사이 에서 랜덤으로 배정해준다.
다음은 포아송 분포이다.
로그에 따라 판매량을 조절해준다.
3.2 데이터 요약 해보기
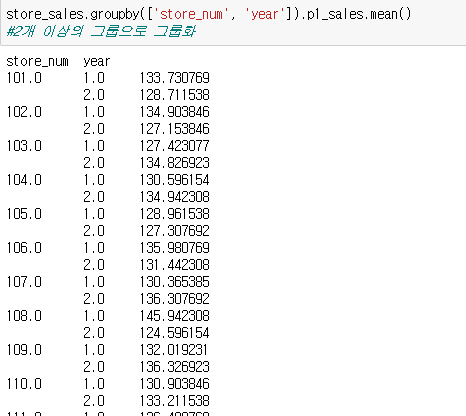
groupby를 사용했고 그룹은 store_num으로 묶었다. 계산함수는 mean을 써서 평균을 계산하였다. 2개 이상의 그룹으로 그룹화를 진행했다. 리스트 []안에 index명을 넣어줬다.
그룹화는 여기까지만 하고 뒤에서도 더 다룬다.
기본 정렬에 대해 좀 다뤄보자.
정렬은 기본적으로 내림차순이다. sort(정렬)=false로 한다면 정렬을 하지 않는다.
이제 시각화를 해보자.
p1_table을 만들어준다.plot을 써서 막대그래프를 그릴수가 있다. 간격이 떨어져있는것을 보고 막대 그래프인것을 파악할수가있다.크로스탭을 사용해보자. 이걸봐서는 잘 이해가 안됨으로 다음 사진을 봐보자.
crosstab은 다음과 같이 교차하는 부분을 계산해주는 함수이다.이 사진을 다시 보자면 2.19달러를 기준으로 했을때 price와 promo의 교차는 0이 358개 1이 41개이다. 따라서 총 합은 399개이고 막대그래프도 y축이 400에 해당되는것을 느낄수가 있다.groupby를 사용해서 요약을 해도 되고 unstack을 써서 엑셀처럼 보이게 하는것도 좋다.
계산 함수
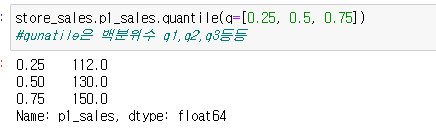
흔히 알고있는것은 넘어가구 var는 분산 std는 표준편차 mad는 산포도, 측정값과 평균사이의 거리의 평균이다.MAD에 대한 설명그리고 분위수가 나온다. 분위수는 25%, 50% ...등등 그때의 값을 계산해준다.함수를 하나 만들어보자 75%의 값에서 25%의 값을 빼주는 함수이다.
3.3 데이터 프레임 요약 해보기
describe는 위에서 했으니까 빼구 iloc, 모든행 + 3~(9-1)열까지 보여준다.
axis를 통해서 기본행에 대해서 요약값을 보여준다.
3.4데이터 프레임 시각화 하기
hist를 사용해서 히스토그램을 그릴수있다.x,y,제목을 추가할수도 있다다른 요소들도 추가해서 히스토그램을 꾸밀수도 있다box_plot을 통해서 iqr을 보여주는 수염이 있는 box도 생성할수있다.정규성 확인을 위해서 도면을 그릴수도 있는데 약간 부족해보인다.아까보다는 정규성이 우수해진것을 느낄수가 있다.natural_earth를 사용해서 지도도 그릴수가 있다.