7장 선형 모델
놀이공원데이터 - 상관관계를 분석할 예정입니다.
서비스의 특징에 대한 고객 만족도와 전반적인 경험 간의 관계를 발견해볼려고 합니다.
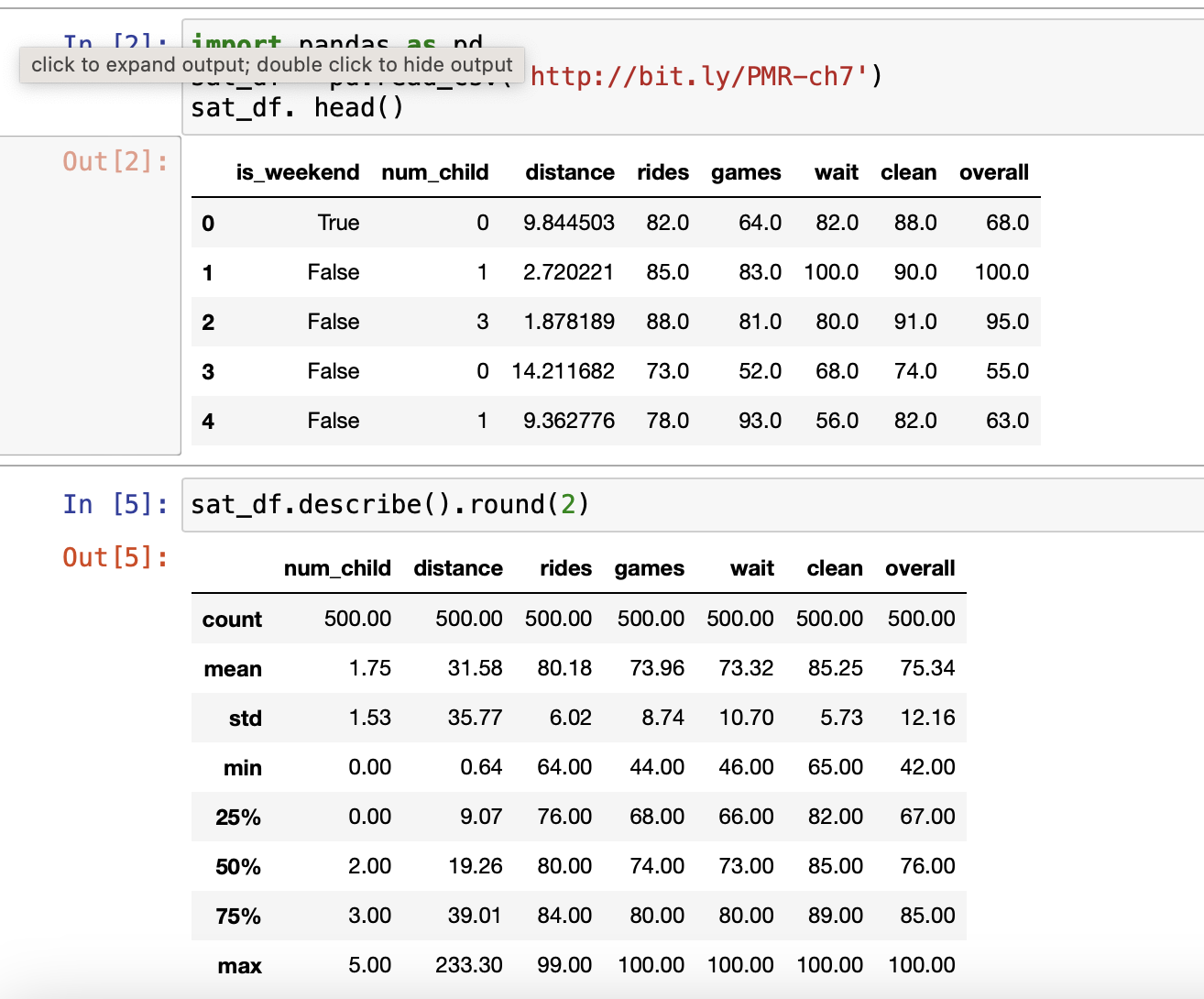

하나만 bool이고 나머지는 inf나 float로 구성
데이터 변수 파악을 위해 시각화를 함
하나만 bool이기 때문에 0 or 1로 만들고

7.2.1 예비 데이터 검사
데이터 시각화를 진행함

clean과 ride가 너무 완벽함 ㅎㅎ
강한 양의 상관관계
*여기서 잠깐 상관관계 설명

0.9>r 이상이면 매우 높은 상관관계를 가집니다. r=0.81임으로 따로 조치를 취하지는 않음

ride-x축, overall-y축으로 산점도를 그려보기

7.2.3 전체적인 만족도와 놀이기구 만족도에 관련된 선형 모델을 추정하고 싶음
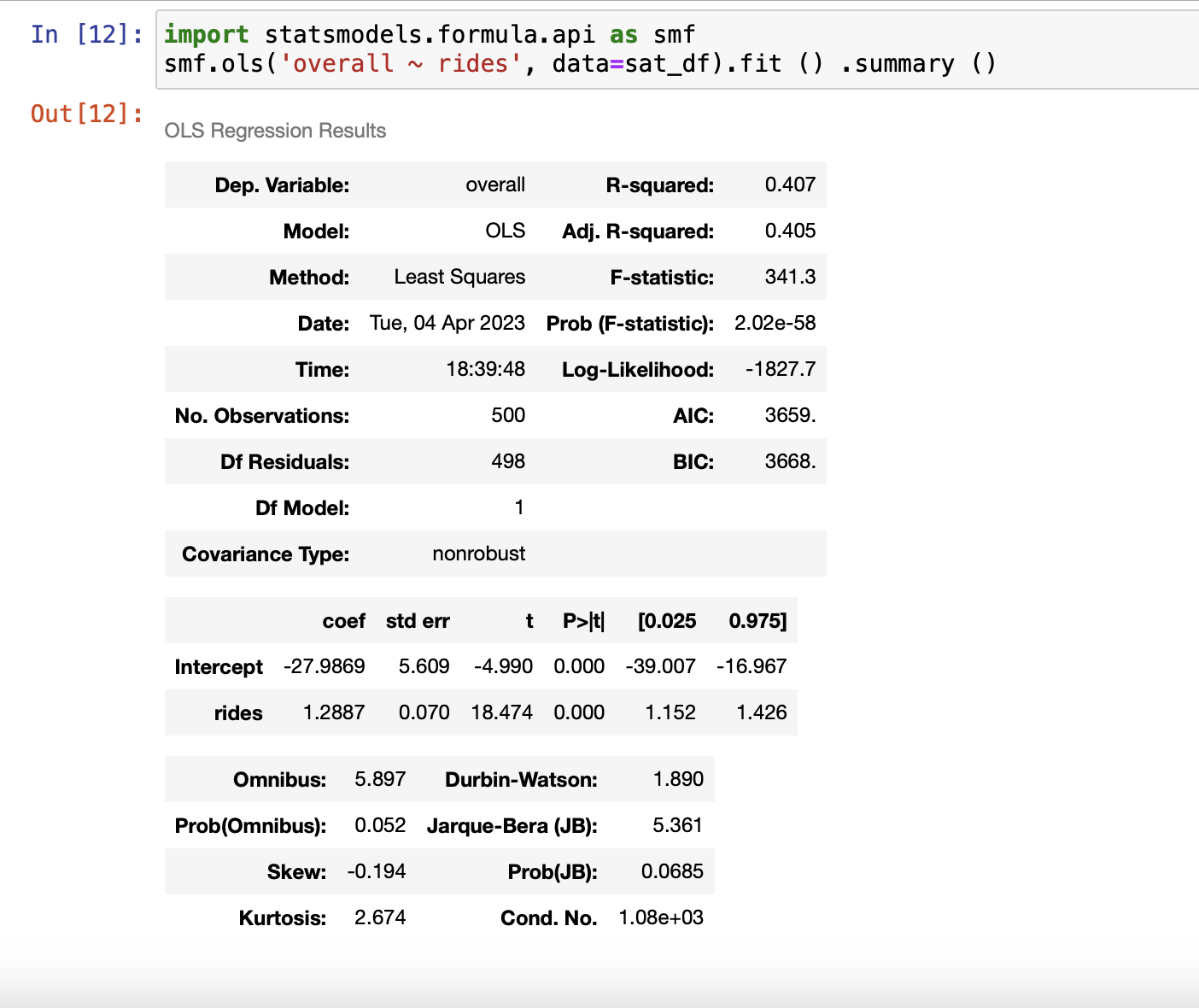
rides-coef가 1.2887
이모델은rides만족도에대해95점을부여한고객이다음과같은전반적인등급을부여한것으로기대한다.
-27.9869 +1.2887*95 = 94.439599999
7.2.4 ols 객체
모델의 선형 적합선을 만들고 싶음
ols.fit()의 결과를 m1에 할당을 함
params를 통해서 아까 나온결과랑 일치하죠? ㅎㅎ

m1.predict() 를 통해서 m1에 대한 예측값을 계산함


그 다음에 신뢰구간 계산도 가능함
m1.conf_int 함수는 주어진 신뢰 수준(일반적으로 95%) 사용
(confidence interval)

이것도 위의 계산과 같음
다음은 상관계수를 계산해보기!
상관 계수(correlation coefficient)

왜 제곱을 할까요? 제곱을 하는것이 더 상관 계수를 해석하는 것이 더욱 쉽기 때문이다.
0.8 < 0.9
0.64 <<< 0.81
잔차에 대한 설명


당연히 작을수록 더 좋겠죠?
잔차가 크면 모델이 잘못 예측될 가능성이 크구 , 개선 해야됨
7.2.5 모델 적합 확인
선형모델의 적합성을 확인하기 위해서는1. 변수와 결과간의 관계가 선형 이어야 한다.


x에대한적합계수가-0.0932.... 이걸 뭘 의미하는지 그래프를 그려보죠 !

오 모델이 이상하군요 !!
7.3 다중 예측자가 있는 선형 모델

R^2=0.595 약 60% 설명이 가능함
R^2 값은 (당연히 양수겠죠) 0과 1 사이의 값을 가지며, 1에 가까울수록 모델이 데이터를 잘 설명한다는 의미입니다.

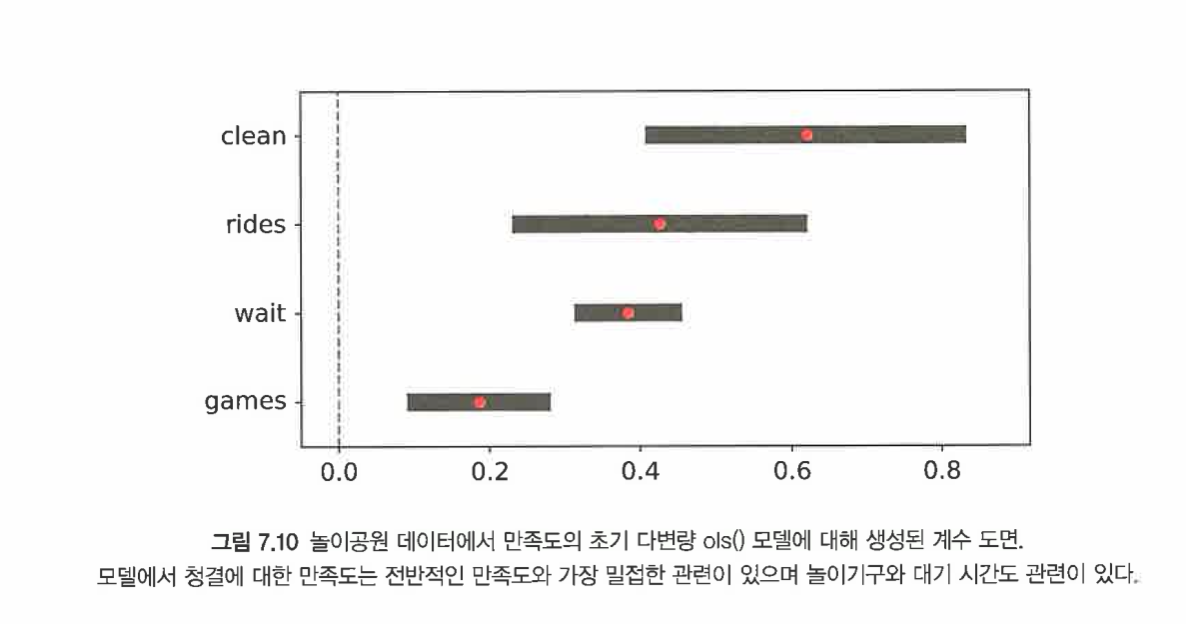
clean이 중요하고 games는 상대적으로 낮다.
7.3.1 모델 비교해보기
이제 2개의 모델을 비교해봅시다.

상관계수가 r^2이 더 높으니 더 좋은 모델이겠죠 ?
근데 변수가 많은것 때문에 m2가 더 높게 나올수도있으니까 (추가된 변수들이 모델의 설명력을 높여주거든요. )
수정 상관계수를 고려해봅시다.

수정 상관계수를 고려해도 m2가 더 좋네요 !!
숫자로만 보지말고 그래프를 그려봅시다.

파란색 점이 더 대각선에 따라 밀집되어있습니다 .m2가 더 데이터의 변동을 설명해줌
7.3.2 모델을 사용해 예측하기
모델 계수를 사용해 설명 변수의 다양한 조합에 대한 overall 결과를 예측해봅시다 !

이 코드는 m2 모델의 Intercept(절편), rides(라이드 수), games(게임 수), wait(대기 시간), clean(청결도)의 회귀 계수를 각각 100으로 대입하여 예측값을 계산하는 코드입니다.
만점인 100점보다 높네요! 모든것을 100점 으로 평가하는 사람은 또한 전체적으로 100점을 줄 가능성이 있다.
7.3.3
점수가 아니라 등급으로 평가될때는 어떻게 모델화 할까?
우리가 일반적으로 알고있는 공식을 사용해보죠 

상대적인 기여도만 고려해본다면 조정된 버전의 sat_df를 만들수있다.
weekend는 요인변수이고 분석을 안해본 num_child는 그대로 둡니다.

describe()를 통해서 표준화된 결과를 확인해봅시다.
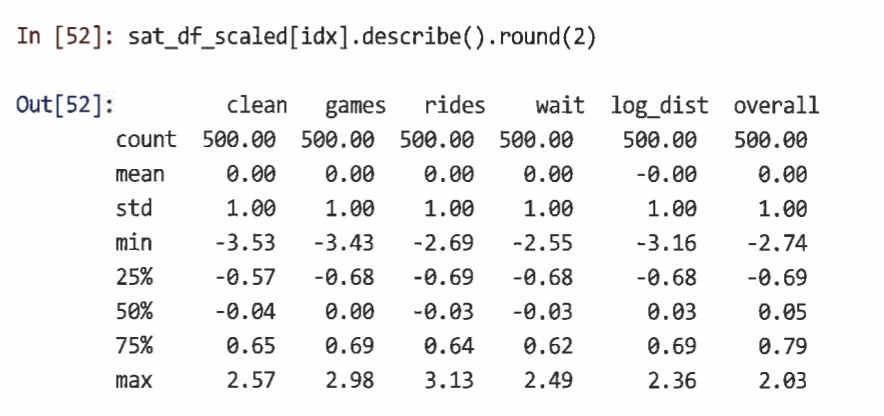
표준화 된거니까 평균은 0이고 ( 평균이 0이 되는 것은 표준화 과정에서 데이터 값들의 평균을 빼기 때문입니다)
평균으로부터 가까워야합니다. 근데 min.max도 크지않고 분산도 작네요 잘 된거 같아요 !
7.4 요인을 예측자로 활용
위의 m2를 좀 더 개선해 볼까요?
1. 주말 방문
2. 거리 차이
3. 자녀 유무 혹 다자녀
위의 모델에서 보다 is_weekend랑 num_child가 추가 되었죠?


log_dist와 num_child가 0보다 훨씬 크죠 ?

num_child를 요인으로 변환하고 모델을 재추정해봅시다.


6개의 계수가 있는데 자녀가 없으면 만족도가 더 낮다는 것을 나타냅니다.
여기서 2개 집단을 선택해서 비교가 가능합니다.
예를들어 아이가 3명있을때와 2명있을때의 만족도 차이는 num_child_3일때가(0.2108-0.2549=-0.0441) 이정도 차이나네요!
7.5 상호 작용 항
rides의 함수와 wait와 has_child의 상호작용 으로 전체를 추정하려면
overall~ rides +. wait:has_child로 공식을 작성 할수 있다


근데 다른게 많이 만들어졌네요 ride:has_child같은......
그래서 삭제를 진행해줍니다.



아이들이 있는 사람들에서 대기 시간이 더 중요한 변수이다.
시각화를 해볼까요?


1. 대기시간 만족도는 어린이가 없는 방문자보다 어린이가 있는 방문자의 전반적인 만족도를 더 잘 예측합니다.
2. clean에 대한 만족은 가장 관련이 높습니다.
7.5.1 기타 구문
상호작용은 :를 쓰는걸 배웠음



7.5.2 과적합
적합 - fitting 과적합 - overfitting
그러면 뭘 over했을까? noise까지 학습하는걸 말합니다.
노이즈(noise)는 데이터에 포함된 임의의 오차나 불확실성을 의미합니다.
즉, 실제 데이터와는 무관한 값이나, 측정이나 수집 과정에서 발생한 오차, 외부 요인 등이
모두 노이즈에 해당됩니다.
(1) 표준오차를 주시하기
표준오차는 모델의 예측 성능을 평가하는 데 도움이 되는 지표이다.
표준오차가 작은 모델이 일반화 성능이 더 좋을 가능성이 높습니다.
따라서, 모델 학습 과정에서 표준오차를 고려하여 모델의 복잡도를 조절한다면 과적합을 방지하고 더 일반화된 모델을 만들 수 있습니다.
(2) 보유할 데이터의 하위집합을 선택하기
보유할 데이터의 일부를 테스트용로 사용하니까 전체 데이터에 대해 모델의 일반화 성능을 검증할 수 있기 때문입니다.
이 방법을 사용하면 모델이 학습 데이터에만 지나치게 맞춰져서 새로운 데이터에 대한 예측 능력이 부족해지는 과적합 문제를 해결할 수 있습니다.
마무리 _ 7.5.3 선형모델의 절차

