8장
8장에서는 3가지 모델을 다룹니다.
온라인 매장 및 매장 내 거래 요약 데이터를 pairgrid를 통해서 시각화 해봅시다.
문제가 많아 보이네요 .....

1. 박스 콕스 변환 - 데이터를 정규분포에 가깝게 만드는것
이를 통해 변수의 선형성을 높이고, 모델의 예측력을 개선할 수 있습니다.

박스콕스 변환에서는 0이 있으면 문제가 되기 때문에 1을 더합니다.(log를 쓰기 때문이죠 )

그리구 scipy 패키지의 boxcox 함수를 사용하여, 입력된 데이터를 박스-콕스 변환합니다.
이 함수는 데이터의 최적 람다 값을 찾아 변환을 수행합니다. 변환된 데이터와 최적 람다 값이 반환됩니다.


온라인 방문은 관련성이 적네요 ...

근데 박스콕스 변환에서 문제가 있어요..
공선성은 독립 변수들 간의 상관 관계가 매우 높아 선형 회귀 모델에서 오류를 일으키거나 모델의 예측 능력을 떨어뜨리는 현상입니다.
8.1.2 공선성 수정
공선성을 계산 해보자

공선성은 5이상이면 완화해야됨으로 5개 정도를 고쳐야겠네요 (왜 5 이상일까?)
VIF가 5라는 것은 특정 독립변수의 분산이 전체 분산에서 5배 정도 더 크다는 것을 의미합니다.
5배 정도 크다면 ... 삭제하거나 완화해야겠죠? ㅎㅎ아래와 같이 완화해줍니다.


공선성을 해결했지만 도움이 되지 않았네요...
8.2 로지스틱 모델
logit함수가 0,1을 의미함 그래서 로지스틱 회귀모델은 binary (이진)입니다!
함수에 대한 기본적인 얘기가 쭉 나옵니다.

함수에 대한 기본적인 얘기가 쭉 나옵니다. -계속-

로짓 함수의 개형입니다.
8.2.2
함수를 공부했으니까 이걸로 분석을 해볼까요 ?

데이터를 불러오죠 !
가설은 "판촉 번들이 시즌권 판매에 영향을 미치는가?"로 가설을 세워보죠
#판촉번들- 묶음판매

coef가 0.3888이라는건
Promo가 YesBundle인 경우 Pass가 YesPass일 확률이 NoBundle인 경우보다 1.47배(=exp(0.3888))높다는 말입니다.

생각을 해본다면 번들조건에 양의계수가 있으면 의미가 있겠죠 ?
그 다음에 odds 승산비를 구해봅시다.


번들이 아닐떄 -0.1922를 사용하고 번들일때 0.3888- 0.1922임으로 위와 같이 계산이 됩니다.
승산비를 해석하는 방법은 1보다 크다면 노출군에서 사건 발생 확률이 비노출군보다 높다
우도(likelihood)는 어떤 모수(parameter)가 주어졌을 때, 해당 모수에서 주어진 데이터(data)가 관측될 확률을 의미합니다.

신뢰구간도 다음과 같이 구할수있다.

데이터를 더 살펴보자,

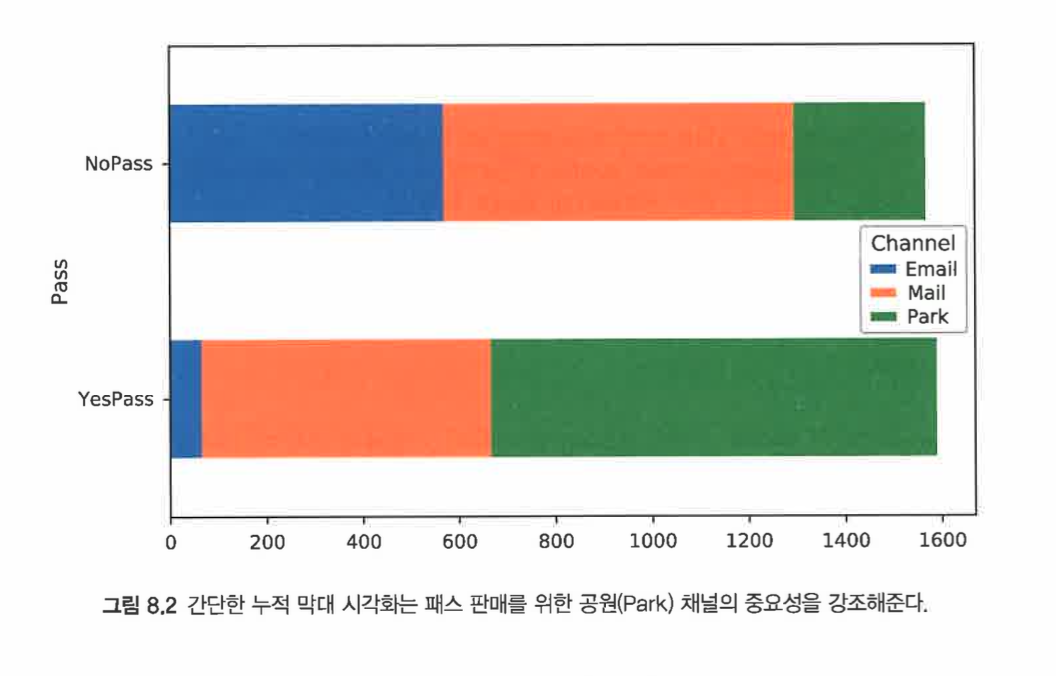
pass별로 그룹화한것. 패스를 구매할때 park가 높은 비중을 차지한다.
그룹화를 다르게 해보자

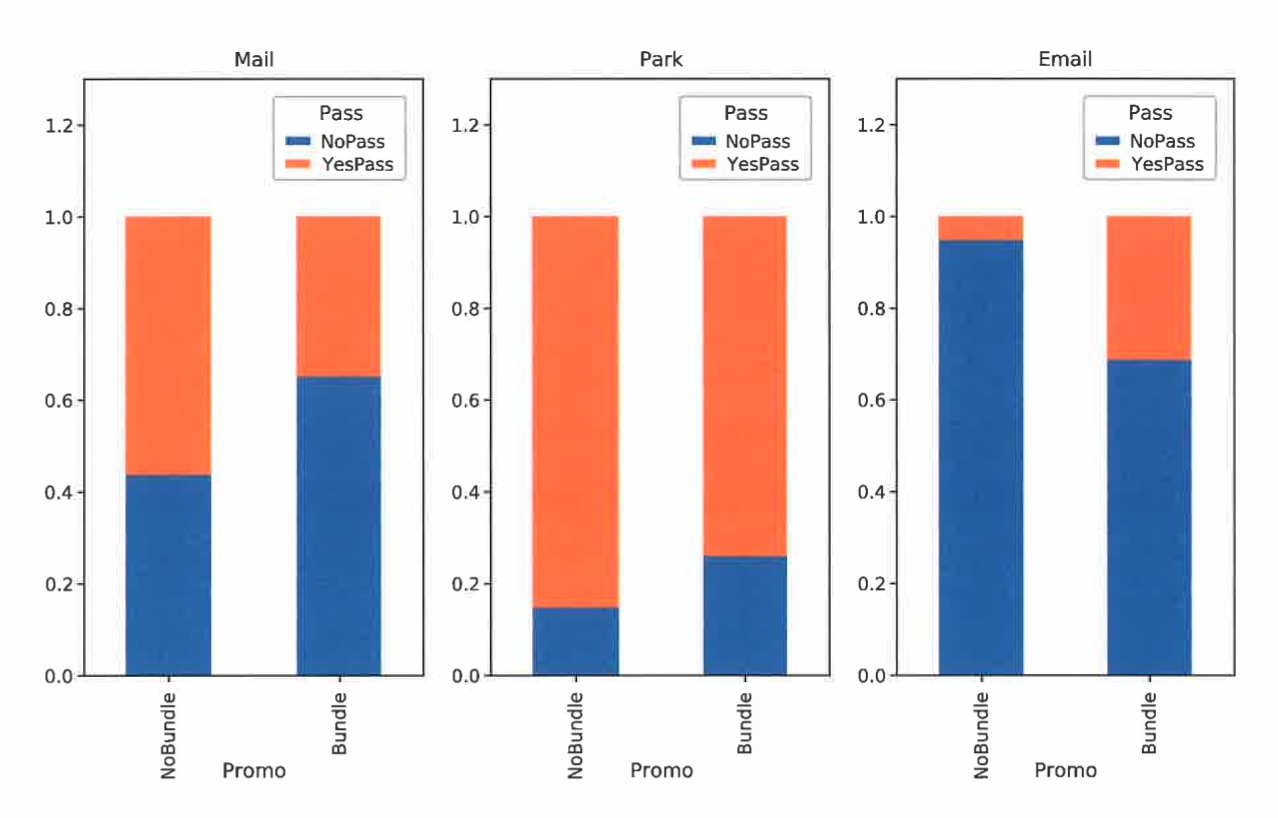
여기서도 마찬가지로 신뢰구간 등등을 구할수있습니다.
8.3
계층적선형모델_HLM 사용해보기
두 개 이상의 특징,수준(level)을 가진 데이터에서 관측치 간의 상관관계를 반영하여 분석.
가설 - 어떤 롤러코스터의 특징이 고객에게 어필할 수 있는가
최대속도(40. 50, 60또는 70mph), 높이(200. 300 또는40피트), 재질유형(나무또는강철), 테마(용또는독수리)

8.3.4
height를 기준으로 점수의 평균을 내봅시다.


height는 너무 높으면 안되구 너무 낮아도 안되구.. 속도는 빠른게 좋겠네요!
하지만 이렇게 특징하나하나씩 가져와 해석을 하는거보다는 더 좋게 해석을 해봅시다.

계수 - 선호도
개별 특징들은 평균적으로 가장우수 하더라도 그 특징들의 모든 정확한 조합을 선호하는 사람은 별로 없을수 도있다.
그니까 그룹별에서 최고의 선호도로 롤러코스터를 만들더라도 그게 최고가 될수없다..
T_wood도 선호도가 거의 0인데 사람들이 관심이 없는걸까요 ?
전체평균과 그룹 내 선호도 수준. 및 개인 선호도를 추정하는 계층적 모델을 사용한다. 8.3.5
ols대신에 mixedlm을 써볼께요
ols- 독립변수들이 종속변수에 영향을 미치는 고정효과만을 고려합니다
mixedlm-다양한 수준의 변동성(heterogeneity)을 반영할 수 있습니다.
고정효과와 랜덤효과가 함께 존재합니다.


ols와 비슷하네요 ...
랜덤효과추정을 해보죠 !
random_effects

고정효과매개변수를데이터프레임에 추가하고 랜덤효과를 추가해보죠

응답자 1의 절편은 2.69-0.92입니다.


최종정리
랜덤효과 해석 -


왼쪽 대각선을 뺴고 높이가 300이고 속도가 60에 강한 상관관계가 있네요 !
결론
개별혹은 그룹화를 모두 추정하는 계층 모델을 고려해야 한다 !.
