9장

perform - 성과
leader - 리더
latest-최신
fun-재미
serious-대단함
bargain -할인
value-가치
trendy-트렌디
rebuy -재구매
brand -브랜드 종류
이렇게 10개의 브랜드 종류를 x 100명이 수행했다
그래서 총 1000명이다


z-정규화
정규화공식인 x-평균/표준편차를 사용해서 정규화 한다
당연히 평균은 0 이다
정규분포곡선은 대칭임으로 중간값도 0이다

corr로 상관관계 표를 그려보자

앞서 브랜드가 10개니까 브랜드를 그룹으로 지정하구 평균을 내봤다.



이걸로 히트맵을 그려보자


해석해 보자 초록색일수록 높고 갈색일수록 낮다.
한눈에 알기 쉬운건 없지만 j 같은경우에는 fun은 높지만 나머지 부분은 다른브랜드보다 낮다는 것을 알수있다.
9.2 주성분 분석 _PCA


random.seed를 써서 xvar를 무작위로 생성하고
yvar에다가 카피를 한다 그 다음에 절반만 남기고 절반을 대체한다. 계속 반복
그다음에 scatter를 사용해 xvar과 yvar에서의 관계를 봐보자


PCA를 직접 써보자

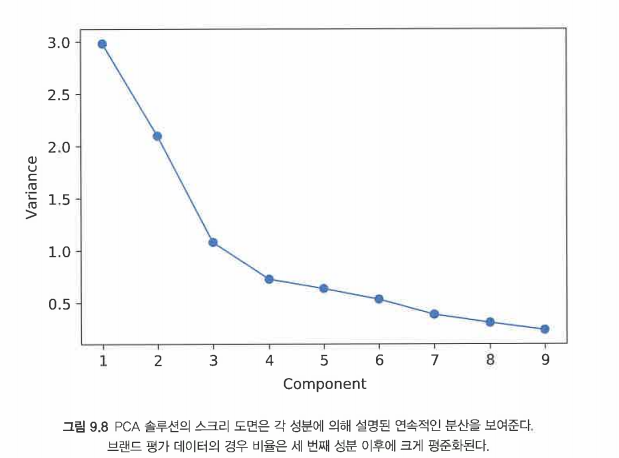
VARIANCE를 보면 62%, 26% 11%이다.
이게 뭘 의미할까


시각화를 해보자


PCA.fit을 사용해서 성분을 찾고 2개의 변수를 만들자.

엘보우 그래프가 나온다.

9.2.4 지각도
브랜드별로 나누고 평균 등급을 구한다.

총평균 등급의 소비자 브랜드 자각도

9.3 탐색적 요인 분석 EFA
구성체 사이의 관계를 평가하는 것이다.
해석 가능한 솔루션을 찾는것이 가장큰 차이이다.

처음에 고유값을 가져왔다.
주성분의 표준편차가 고유값이다.
9.4 다차원 척도법
거리행렬을 입력 받음 (거리행렬 - 데이터 포인트 사이의 거리임)
3차원도 2차원으로 변환이 가능함 그래서 거리계산이 가능!
가장 짧은 거리인 유클리드 거리를 계산한다.
manifold를 통해서 저차원으로 임베딩한다.


비측도 MDS
숫자가 아닌 순위나 범주형 변수일경우에는 metric=false를 쓴다

서수로 표현되어 있고 시각화를 한다면

9.4.2 저차원 임베딩을 사용한 시각화
t-sne - 데이터의 군집(clustering)을 보존하면서, 저차원으로 임베딩합니다. 이를 통해, 고차원 데이터의 복잡한 구조와 패턴을 시각화할 수 있습니다.
umap UMAP은 t-SNE보다 빠르고, 대용량 데이터셋에 대해서도 잘 작동합니다. 또한, UMAP은 데이터의 군집화를 보존하면서, 데이터의 거리를 보다 잘 보존한다는 특징이 있습니다.
비교를 정리하자면 umap은 대규모 데이터셋에 대해 빠르고 정확하게 가능함으로 대규모 데이터 에서는 umap이 가능하다. 또 거리가 민감하면 umap이 더 적합하다. 하지만 클러스터링에 대해 덜 강조함으로 그때마다 특성에 따라 manifold를 선택해야 한다.
