[스터디 1주차] 혼자 공부하는 데이터 분석 with 파이썬(혼공파)
내용설명
1. 요약통계
요약통계는 기술통계라고도 하며 정량적인 수치를 다룬다. (정량적=수치라고 생각해도된다.)
처음에 데이터 파일을 불러오고
파일명.describe() 라고 입력하면 8가지의 통계량이 나온다.

위에서 언급한대로 정량적인 수치만 다루기 때문에 type이 object인것은 나오지 않고 int만 나온다.
타입을 확인하기 위해서는 파일명.info()를 사용하면된다.

2.전처리
그 다음은 전처리인데 대출건수의 min이 0이다.
대출한자료의 데이터인데 대출이 되어있지않는것이다.
이부분은 제거하고 싶다.

ns_book7=ns_book6[ns_book6['도서권수']>0]
# ns_book7에 새로 저장을 하고 ns_book6 도서권수가 0보다 큰 데이터는 빼고 세이브한다.
int형이 아닌 object만 이용해서 추출해도 된다.
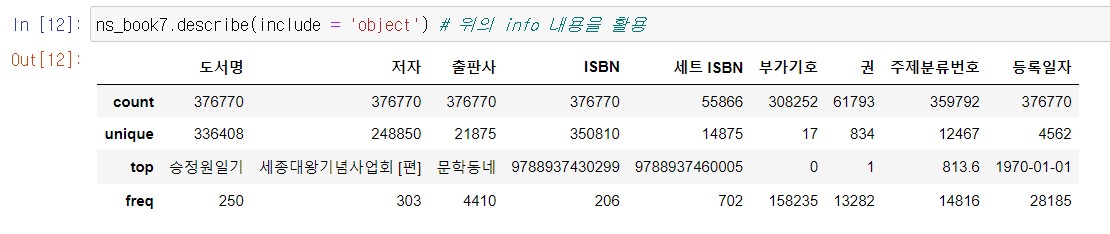
3. 따로 따로 추출하기
describe를 사용해서 8개의 데이터만 추출하는것이 목적이아니라 개별로도 데이터를 추출할 수 있다.
#참고로 판다스와 넘파이의 추출방법은 같을수도 다를수도 있다. 지금은 판다스 기준으로 코딩을 한것이고 넘파이를 이용한 방법은 바로뒤에 나와있다.


만약에 여기서 중복을 제거하고싶을땐 drop_duplicates()를 사용하면 된다.
ns_book7['대출건수'].drop_duplicates.median()
3-1.분위수
분위수는 하위몇%에 해당되는 값인지 계산해주는것이다.
판다스에서는 quantile을 사용하는데 quantile(0.25)면 하위 25%에 해당되는값이 나온다.
공부를 하면서 분위수와 백분위는 같지 않으니 그것의 차이를 알아두자!

3-2.분산과 표준편차

간단히 말하자면 분산이 작다면 데이터의 분포 정도가 고르다는것이다.
표준편차의 제곱은 분산이다.
파일명.var()과 파일명.std()를 사용하면된다.
4.데이터프레임에 적용해보기
그러면 ns_book7.mean()을 해보자. 이렇게 한다면 오류가 나올것이다.
object이랑 int로 구성되어있기때문에 문자형은 평균을 구하기가 힘들다.
따라서 수치형만 있는것을 고를것임으로 ns_book7.mean(numeric_only=True)라고 해주면된다.
5.넘파이에서의 통계량
처음에 import numpy as np로 넘파이를 불러와주고

np.mean(ns_book['대출건수'])를 해주면 된다.

나머지 요약통계 수치도 그대로 하면된다.
# 기억해야할점은 넘파이의 분산은 n으로 나누고 판다스의 분산은 n-1로 나눈다. 그래서 결과값이 다르게 나올테니 두개가 같게할려면 ddof=0 or ddof=1로 지정해주면된다.
실제적용
Pedal Me Bicycle Delivers Data set 이용한 요약 통계 구하기 ( 수치형 데이터 )